Calculating Covariance with Python and Numpy

I am trying to figure out how to calculate covariance with the Python Numpy function cov. When I pass it two one-dimentional arrays, I get back a 2x2 matrix of results. I don't know what to do with that. I'm not great at statistics, but I believe covariance in such a situation should be a single number. This is what I am looking for. I wrote my own:
def cov(a, b):
if len(a) != len(b):
return
a_mean = np.mean(a)
b_mean = np.mean(b)
sum = 0
for i in range(0, len(a)):
sum += ((a[i] - a_mean) * (b[i] - b_mean))
return sum/(len(a)-1)
That works, but I figure the Numpy version is much more efficient, if I could figure out how to use it.
Does anybody know how to make the Numpy cov function perform like the one I wrote?
Thanks,
Dave
Answer

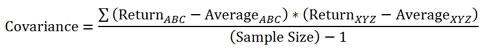{kind=link}
When a and b are 1-dimensional sequences, numpy.cov(a,b)[0][1] is equivalent to your cov(a,b).
The 2x2 array returned by np.cov(a,b) has elements equal to
cov(a,a) cov(a,b)
cov(a,b) cov(b,b)
(where, again, cov is the function you defined above.)