Why do we need message brokers like RabbitMQ over a database like PostgreSQL?

I am new to message brokers like RabbitMQ which we can use to create tasks / message queues for a scheduling system like Celery.
Now, here is the question:
I can create a table in PostgreSQL which can be appended with new tasks and consumed by the consumer program like Celery.
Why on earth would I want to setup a whole new tech for this like RabbitMQ?
Now, I believe scaling cannot be the answer since our database like PostgreSQL can work in a distributed environment.
I googled for what problems does the database poses for the particular problem, and I found:
- polling keeps the database busy and low performing
- locking of the table -> again low performing
- millions of rows of tasks -> again, polling is low performing
Now, how does RabbitMQ or any other message broker like that solves these problems?
Also, I found out that AMQP protocol is what it follows. What's great in that?
Can Redis also be used as a message broker? I find it more analogous to Memcached than RabbitMQ.
Please shed some light on this!
Answer

Rabbit's queues reside in memory and will therefore be much faster than implementing this in a database. A (good)dedicated message queue should also provide essential queueing related features such as throttling/flow control, and the ability to choose different routing algorithms, to name a couple(rabbit provides these and more). Depending on the size of your project, you may also want the message passing component separate from your database, so that if one component experiences heavy load, it need not hinder the other's operation.
As for the problems you mentioned:
polling keeping the database buzy and low performing: Using Rabbitmq, producers can push updates to consumers which is far more performant than polling. Data is simply sent to the consumer when it needs to be, eliminating the need for wasteful checks.
locking of the table -> again low performing: There is no table to lock :P
millions of rows of task -> again polling is low performing: As mentioned above, Rabbitmq will operate faster as it resides RAM, and provides flow control. If needed, it can also use the disk to temporarily store messages if it runs out of RAM. After 2.0, Rabbit has significantly improved on its RAM usage. Clustering options are also available.
In regards to AMQP, I would say a really cool feature is the "exchange", and the ability for it to route to other exchanges. This gives you more flexibility and enables you to create a wide array of elaborate routing typologies which can come in very handy when scaling. For a good example, see:

(source: springsource.com)
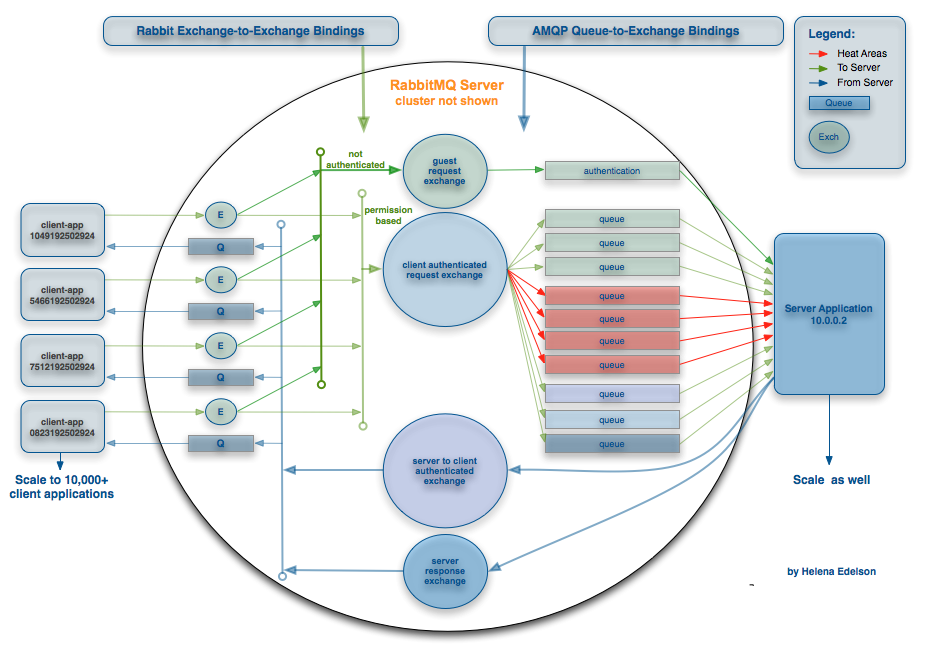{kind=link}
Finally, in regards to redis, yes, it can be used as a message broker, and can do well. However, Rabbitmq has more message queuing features than redis, as rabbitmq was built from the ground up to be a full-featured enterprise-level dedicated message queue. Redis on the other hand was primarily created to be an in-memory key-value store(though it does much more than that now; its even referred to as a swiss army knife). Still, I've read/heard many people achieving good results with Redis for smaller sized projects, but haven't heard much about it in larger applications.
Here is an example of redis being used in a long-polling chat implementation: http://eflorenzano.com/blog/2011/02/16/technology-behind-convore/