Save ML model for future usage

I was applying some Machine Learning algorithms like Linear Regression, Logistic Regression, and Naive Bayes to some data, but I was trying to avoid using RDDs and start using DataFrames because the RDDs are slower than Dataframes under pyspark (see pic 1).
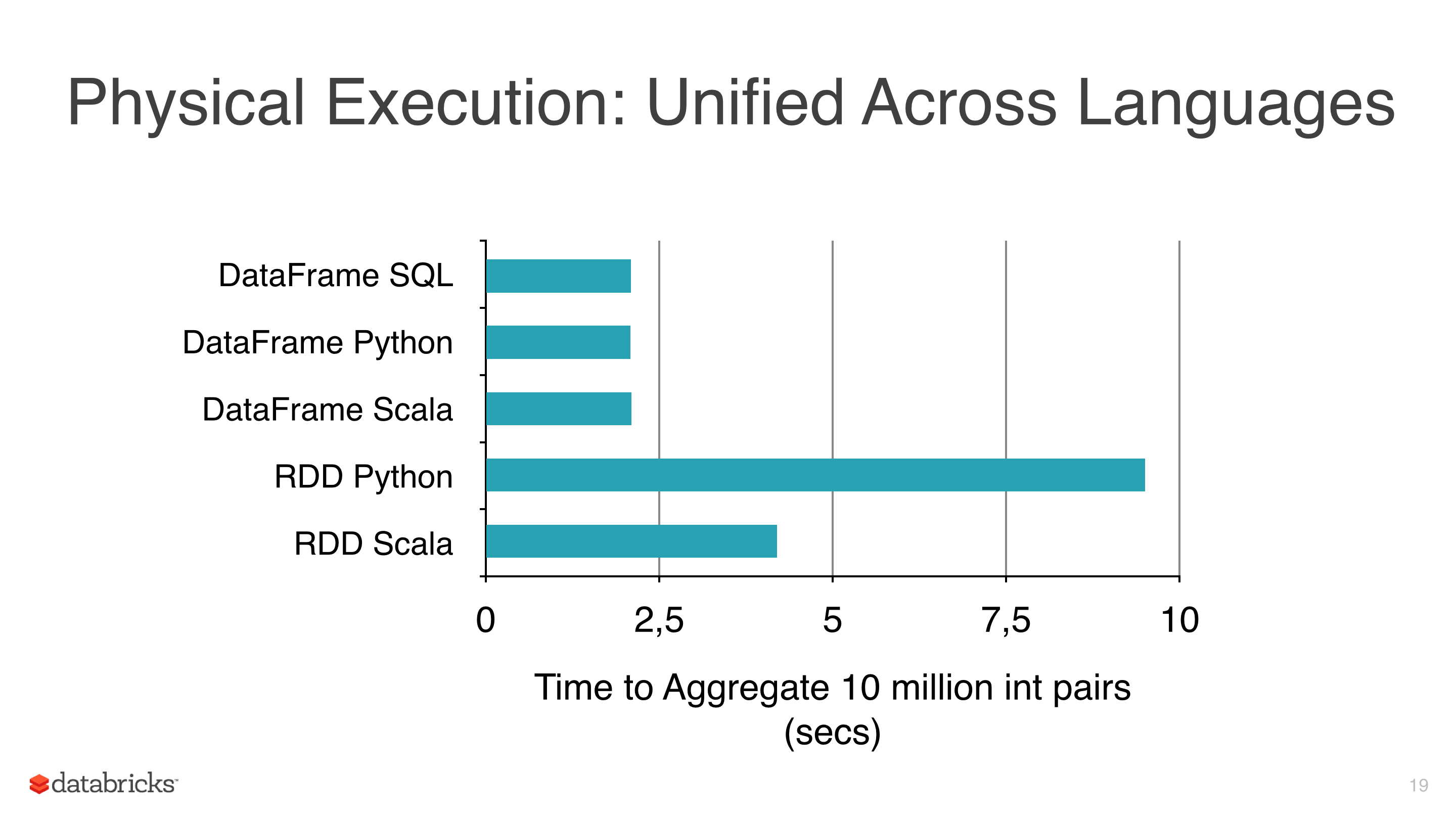
The other reason why I am using DataFrames is because the ml library has a class very useful to tune models which is CrossValidator this class returns a model after fitting it, obviously this method has to test several scenarios, and after that returns a fitted model (with the best combinations of parameters).
The cluster I use isn't so large and the data is pretty big and some fitting take hours so I want to save this models to reuse them later, but I haven't realized how, is there something I am ignoring?
Notes:
- The mllib's model classes have a save method (i.e. NaiveBayes), but mllib does not have CrossValidator and use RDDs so I am avoiding it premeditatedly.
- The current version is spark 1.5.1.
Answer

Spark 2.0.0+
At first glance all Transformers and Estimators implement MLWritable with the following interface:
def write: MLWriter
def save(path: String): Unit
and MLReadable with the following interface
def read: MLReader[T]
def load(path: String): T
This means that you can use save method to write model to disk, for example
import org.apache.spark.ml.PipelineModel
val model: PipelineModel
model.save("/path/to/model")
and read it later:
val reloadedModel: PipelineModel = PipelineModel.load("/path/to/model")
Equivalent methods are also implemented in PySpark with MLWritable / JavaMLWritable and MLReadable / JavaMLReadable respectively:
from pyspark.ml import Pipeline, PipelineModel
model = Pipeline(...).fit(df)
model.save("/path/to/model")
reloaded_model = PipelineModel.load("/path/to/model")
SparkR provides write.ml / read.ml functions, but as of today, these are not compatible with other supported languages - SPARK-15572.
Note that the loader class has to match the class of the stored PipelineStage. For example if you saved LogisticRegressionModel you should use LogisticRegressionModel.load not LogisticRegression.load.
If you use Spark <= 1.6.0 and experience some issues with model saving I would suggest switching version.
Additionally to the Spark specific methods there is a growing number of libraries designed to save and load Spark ML models using Spark independent methods. See for example How to serve a Spark MLlib model?.
Spark >= 1.6
Since Spark 1.6 it's possible to save your models using the save method. Because almost every model implements the MLWritable interface. For example, LinearRegressionModel has it, and therefore it's possible to save your model to the desired path using it.
Spark < 1.6
I believe you're making incorrect assumptions here.
Some operations on a DataFrames can be optimized and it translates to improved performance compared to plain RDDs. DataFrames provide efficient caching and SQLish API is arguably easier to comprehend than RDD API.
ML Pipelines are extremely useful and tools like cross-validator or different evaluators are simply must-have in any machine pipeline and even if none of the above is particularly hard do implement on top of low level MLlib API it is much better to have ready to use, universal and relatively well tested solution.
So far so good, but there are a few problems:
- as far as I can tell simple operations on a
DataFrameslikeselectorwithColumndisplay similar performance to its RDD equivalents likemap, - in some cases growing the number of columns in a typical pipeline can actually degrade performance compared to well tuned low level transformations. You can of course add drop-column-transformers on the way to correct for that,
- many ML algorithms, including
ml.classification.NaiveBayesare simply wrappers around itsmllibAPI, - PySpark ML/MLlib algorithms delegate actual processing to its Scala counterparts,
- last but not least RDD is still out there, even if well hidden behind DataFrame API
I believe that at the end of the day what you get by using ML over MLLib is quite elegant, high level API. One thing you can do is to combine both to create a custom multi-step pipeline:
- use ML to load, clean and transform data,
- extract required data (see for example extractLabeledPoints method) and pass to
MLLibalgorithm, - add custom cross-validation / evaluation
- save
MLLibmodel using a method of your choice (Spark model or PMML)
It is not an optimal solution, but is the best one I can think of given a current API.