How can I further optimize a derived table query which performs better than the JOINed equivalent?

UPDATE: I found a solution. See my Answer below.
My Question
How can I optimize this query to minimize my downtime? I need to update over 50 schemas with the number of tickets ranging from 100,000 to 2 million. Is it advisable to attempt to set all fields in tickets_extra at the same time? I feel that there is a solution here that I'm just not seeing. Ive been banging my head against this problem for over a day.
Also, I initially tried without using a sub SELECT, but the performance was much worse than what I currently have.
Background
I'm trying to optimize my database for a report that needs to be run. The fields I need to aggregate on are very expensive to calculate, so I am denormalizing my existing schema a bit to accommodate this report. Note that I simplified the tickets table quite a bit by removing a few dozen irrelevant columns.
My report will be aggregating ticket counts by Manager When Created and Manager When Resolved. This complicated relationship is diagrammed here:

(source: mosso.com)
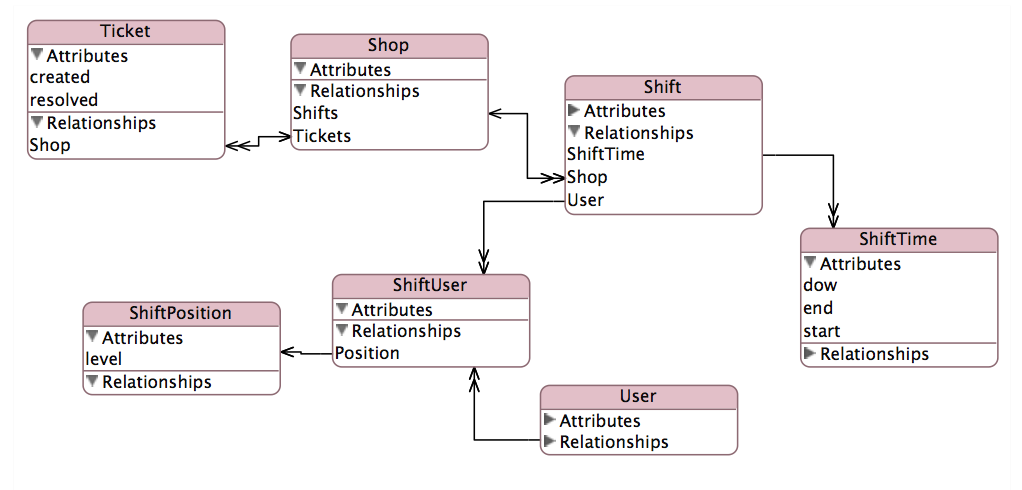{kind=link}
To avoid the half dozen nasty joins required to calculate this on-the-fly I've added the following table to my schema:
mysql> show create table tickets_extra\G
*************************** 1. row ***************************
Table: tickets_extra
Create Table: CREATE TABLE `tickets_extra` (
`ticket_id` int(11) NOT NULL,
`manager_created` int(11) DEFAULT NULL,
`manager_resolved` int(11) DEFAULT NULL,
PRIMARY KEY (`ticket_id`),
KEY `manager_created` (`manager_created`,`manager_resolved`),
KEY `manager_resolved` (`manager_resolved`,`manager_created`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
The problem now is, I haven't been storing this data anywhere. The manager was always calculated dynamically. I have millions of tickets across several databases with the same schema that need to have this table populated. I want to do this in as efficient a way as possible, but have been unsuccessful in optimizing the queries I'm using to do so:
INSERT INTO tickets_extra (ticket_id, manager_created)
SELECT
t.id,
su.user_id
FROM (
SELECT
t.id,
shift_times.shift_id AS shift_id
FROM tickets t
JOIN shifts ON t.shop_id = shifts.shop_id
JOIN shift_times ON (shifts.id = shift_times.shift_id
AND shift_times.dow = DAYOFWEEK(t.created)
AND TIME(t.created) BETWEEN shift_times.start AND shift_times.end)
) t
LEFT JOIN shifts_users su ON t.shift_id = su.shift_id
LEFT JOIN shift_positions ON su.shift_position_id = shift_positions.id
WHERE shift_positions.level = 1
This query takes over an hour to run on a schema that has > 1.7 million tickets. This is unacceptable for the maintenance window I have. Also, it doesn't even handle calculating the manager_resolved field, as attempting to combine that into the same query pushes the query time into the stratosphere. My current inclination is to keep them separate, and use an UPDATE to populate the manager_resolved field, but I'm not sure.
Finally, here is the EXPLAIN output of the SELECT portion of that query:
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: <derived2>
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 167661
Extra:
*************************** 2. row ***************************
id: 1
select_type: PRIMARY
table: su
type: ref
possible_keys: shift_id_fk_idx,shift_position_id_fk_idx
key: shift_id_fk_idx
key_len: 4
ref: t.shift_id
rows: 5
Extra: Using where
*************************** 3. row ***************************
id: 1
select_type: PRIMARY
table: shift_positions
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 6
Extra: Using where; Using join buffer
*************************** 4. row ***************************
id: 2
select_type: DERIVED
table: t
type: ALL
possible_keys: fk_tickets_shop_id
key: NULL
key_len: NULL
ref: NULL
rows: 173825
Extra:
*************************** 5. row ***************************
id: 2
select_type: DERIVED
table: shifts
type: ref
possible_keys: PRIMARY,shop_id_fk_idx
key: shop_id_fk_idx
key_len: 4
ref: dev_acmc.t.shop_id
rows: 1
Extra:
*************************** 6. row ***************************
id: 2
select_type: DERIVED
table: shift_times
type: ref
possible_keys: shift_id_fk_idx
key: shift_id_fk_idx
key_len: 4
ref: dev_acmc.shifts.id
rows: 4
Extra: Using where
6 rows in set (6.30 sec)
Thank you so much for reading!
Answer
Well, I found a solution. It took a lot of experimentation, and I think a good bit of blind luck, but here it is:
CREATE TABLE magic ENGINE=MEMORY
SELECT
s.shop_id AS shop_id,
s.id AS shift_id,
st.dow AS dow,
st.start AS start,
st.end AS end,
su.user_id AS manager_id
FROM shifts s
JOIN shift_times st ON s.id = st.shift_id
JOIN shifts_users su ON s.id = su.shift_id
JOIN shift_positions sp ON su.shift_position_id = sp.id AND sp.level = 1
ALTER TABLE magic ADD INDEX (shop_id, dow);
CREATE TABLE tickets_extra ENGINE=MyISAM
SELECT
t.id AS ticket_id,
(
SELECT m.manager_id
FROM magic m
WHERE DAYOFWEEK(t.created) = m.dow
AND TIME(t.created) BETWEEN m.start AND m.end
AND m.shop_id = t.shop_id
) AS manager_created,
(
SELECT m.manager_id
FROM magic m
WHERE DAYOFWEEK(t.resolved) = m.dow
AND TIME(t.resolved) BETWEEN m.start AND m.end
AND m.shop_id = t.shop_id
) AS manager_resolved
FROM tickets t;
DROP TABLE magic;
Lengthy Explanation
Now, I'll explain why this works, and my relative though process and steps to get here.
First, I knew the query I was trying was suffering because of the huge derived table, and the subsequent JOINs onto this. I was taking my well-indexed tickets table and joining all the shift_times data onto it, then letting MySQL chew on that while it attempts to join the shifts and shift_positions table. This derived behemoth would be up to a 2 million row unindexed mess.
Now, I knew this was happening. The reason I was going down this road though was because the "proper" way to do this, using strictly JOINs was taking an even longer amount of time. This is due to the nasty bit of chaos required to determine who the manager of a given shift is. I have to join down to shift_times to find out what the correct shift even is, while simultaneously joining down to shift_positions to figure out the user's level. I don't think the MySQL optimizer handles this very well, and ends up creating a HUGE monstrosity of a temporary table of the joins, then filtering out what doesn't apply.
So, as the derived table seemed to be the "way to go" I stubbornly persisted in this for a while. I tried punting it down into a JOIN clause, no improvement. I tried creating a temporary table with the derived table in it, but again it was too slow as the temp table was unindexed.
I came to realize that I had to handle this calculation of shift, times, positions sanely. I thought, maybe a VIEW would be the way to go. What if I created a VIEW that contained this information: (shop_id, shift_id, dow, start, end, manager_id). Then, I would simply have to join the tickets table by shop_id and the whole DAYOFWEEK/TIME calculation, and I'd be in business. Of course, I failed to remember that MySQL handles VIEWs rather assily. It doesn't materialize them at all, it simply runs the query you would have used to get the view for you. So by joining tickets onto this, I was essentially running my original query - no improvement.
So, instead of a VIEW I decided to use a TEMPORARY TABLE. This worked well if I only fetched one of the managers (created or resolved) at a time, but it was still pretty slow. Also, I found out that with MySQL you can't refer to the same table twice in the same query (I would have to join my temporary table twice to be able to differentiate between manager_created and manager_resolved). This is a big WTF, as I can do it as long as I don't specify "TEMPORARY" - this is where the CREATE TABLE magic ENGINE=MEMORY came into play.
With this pseudo temporary table in hand, I tried my JOIN for just manager_created again. It performed well, but still rather slow. Yet, when I JOINed again to get manager_resolved in the same query the query time ticked back up into the stratosphere. Looking at the EXPLAIN showed the full table scan of tickets (rows ~2mln), as expected, and the JOINs onto the magic table at ~2,087 each. Again, I seemed to be running into fail.
I now began to think about how to avoid the JOINs altogether and that's when I found some obscure ancient message board post where someone suggested using subselects (can't find the link in my history). This is what led to the second SELECT query shown above (the tickets_extra creation one). In the case of selecting just a single manager field, it performed well, but again with both it was crap. I looked at the EXPLAIN and saw this:
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: t
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 173825
Extra:
*************************** 2. row ***************************
id: 3
select_type: DEPENDENT SUBQUERY
table: m
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 2037
Extra: Using where
*************************** 3. row ***************************
id: 2
select_type: DEPENDENT SUBQUERY
table: m
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 2037
Extra: Using where
3 rows in set (0.00 sec)
Ack, the dreaded DEPENDENT SUBQUERY. It's often suggested to avoid these, as MySQL will usually execute them in an outside-in fashion, executing the inner query for every row of the outer. I ignored this, and wondered: "Well... what if I just indexed this stupid magic table?". Thus, the ADD index (shop_id, dow) was born.
Check this out:
mysql> CREATE TABLE magic ENGINE=MEMORY
<snip>
Query OK, 3220 rows affected (0.40 sec)
mysql> ALTER TABLE magic ADD INDEX (shop_id, dow);
Query OK, 3220 rows affected (0.02 sec)
mysql> CREATE TABLE tickets_extra ENGINE=MyISAM
<snip>
Query OK, 1933769 rows affected (24.18 sec)
mysql> drop table magic;
Query OK, 0 rows affected (0.00 sec)
Now THAT'S what I'm talkin' about!
Conclusion
This is definitely the first time I've created a non-TEMPORARY table on the fly, and INDEXed it on the fly, simply to do a single query efficiently. I guess I always assumed that adding an index on the fly is a prohibitively expensive operation. (Adding an index on my tickets table of 2mln rows can take over an hour). Yet, for a mere 3,000 rows this is a cakewalk.
Don't be afraid of DEPENDENT SUBQUERIES, creating TEMPORARY tables that really aren't, indexing on the fly, or aliens. They can all be good things in the right situation.
Thanks for all the help StackOverflow. :-D