pythonic implementation of Bayesian networks for a specific application

This is why I'm asking this question: Last year I made some C++ code to compute posterior probabilities for a particular type of model (described by a Bayesian network). The model worked pretty well and some other people started to use my software. Now I want to improve my model. Since I'm already coding slightly different inference algorithms for the new model, I decided to use python because runtime wasn't critically important and python may let me make more elegant and manageable code.
Usually in this situation I'd search for an existing Bayesian network package in python, but the inference algorithms I'm using are my own, and I also thought this would be a great opportunity to learn more about good design in python.
I've already found a great python module for network graphs (networkx), which allows you to attach a dictionary to each node and to each edge. Essentially, this would let me give nodes and edges properties.
For a particular network and it's observed data, I need to write a function that computes the likelihood of the unassigned variables in the model.
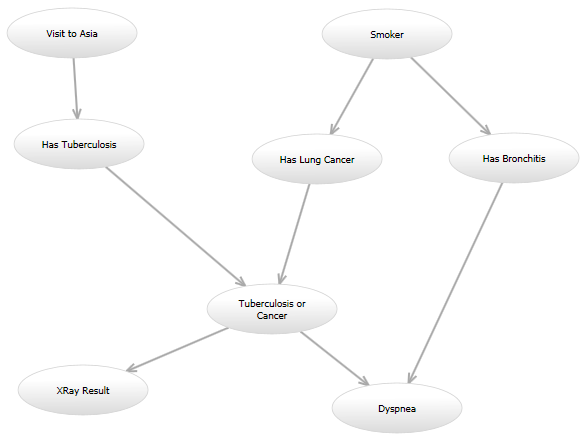
For instance, in the classic "Asia" network (http://www.bayesserver.com/Resources/Images/AsiaNetwork.png), with the states of "XRay Result" and "Dyspnea" known, I need to write a function to compute the likelihood that the other variables have certain values (according to some model).
Here is my programming question: I'm going to try a handful of models, and in the future it's possible I'll want to try another model after that. For instance, one model might look exactly like the Asia network. In another model, a directed edge might be added from "Visit to Asia" to "Has Lung Cancer." Another model might use the original directed graph, but the probability model for the "Dyspnea" node given the "Tuberculosis or Cancer" and "Has Bronchitis" nodes might be different. All of these models will compute the likelihood in a different way.
All the models will have substantial overlap; for instance, multiple edges going into an "Or" node will always make a "0" if all inputs are "0" and a "1" otherwise. But some models will have nodes that take on integer values in some range, while others will be boolean.
In the past I've struggled with how to program things like this. I'm not going to lie; there's been a fair amount of copied and pasted code and sometimes I've needed to propagate changes in a single method to multiple files. This time I really want to spend the time to do this the right way.
Some options:
- I was already doing this the right way. Code first, ask questions later. It's faster to copy and paste the code and have one class for each model. The world is a dark and disorganized place...
- Each model is its own class, but also a subclass of a general BayesianNetwork model. This general model will use some functions that are going to be overridden. Stroustrup would be proud.
- Make several functions in the same class that compute the different likelihoods.
- Code a general BayesianNetwork library and implement my inference problems as specific graphs read in by this library. The nodes and edges should be given properties like "Boolean" and "OrFunction" which, given known states of the parent node, can be used to compute the probabilities of different outcomes. These property strings, like "OrFunction" could even be used to look up and call the right function. Maybe in a couple of years I'll make something similar to the 1988 version of Mathematica!
Thanks a lot for your help.
Update: Object oriented ideas help a lot here (each node has a designated set of predecessor nodes of a certain node subtype, and each node has a likelihood function that computes its likelihood of different outcome states given the states of the predecessor nodes, etc.). OOP FTW!
Answer

{kind=link}
I've been working on this kind of thing in my spare time for quite a while. I think I'm on my third or fourth version of this same problem right now. I'm actually getting ready to release another version of Fathom (https://github.com/davidrichards/fathom/wiki) with dynamic bayesian models included and a different persistence layer.
As I've tried to make my answer clear, it's gotten quite long. I apologize for that. Here's how I've been attacking the problem, which seems to answer some of your questions (somewhat indirectly):
I've started with Judea Pearl's breakdown of belief propagation in a Bayesian Network. That is, it's a graph with prior odds (causal support) coming from parents and likelihoods (diagnostic support) coming from children. In this way, the basic class is just a BeliefNode, much like what you described with an extra node between BeliefNodes, a LinkMatrix. In this way, I explicitly choose the type of likelihood I'm using by the type of LinkMatrix I use. It makes it easier to explain what the belief network is doing afterwards as well as keeps the computation simpler.
Any subclassing or changes that I'd make to the basic BeliefNode would be for binning continuous variables, rather than changing propagation rules or node associations.
I've decided on keeping all data inside the BeliefNode, and only fixed data in the LinkedMatrix. This has to do with ensuring that I maintain clean belief updates with minimal network activity. This means that my BeliefNode stores:
- an array of children references, along with the filtered likelihoods coming from each child and the link matrix that is doing the filtering for that child
- an array of parent references, along with the filtered prior odds coming from each parent and the link matrix that is doing the filtering for that parent
- the combined likelihood of the node
- the combined prior odds of the node
- the computed belief, or posterior probability
- an ordered list of attributes that all prior odds and likelihoods adhere to
The LinkMatrix can be constructed with a number of different algorithms, depending on the nature of the relationship between the nodes. All of the models that you're describing would just be different classes that you'd employ. Probably the easiest thing to do is default to an or-gate, and then choose other ways to handle the LinkMatrix if we have a special relationship between the nodes.
I use MongoDB for persistence and caching. I access this data inside of an evented model for speed and asynchronous access. This makes the network fairly performant while also having the opportunity to be very large if it needs to be. Also, since I'm using Mongo in this way, I can easily create a new context for the same knowledge base. So, for example, if I have a diagnostic tree, some of the diagnostic support for a diagnosis will come from a patient's symptoms and tests. What I do is create a context for that patient and then propagate my beliefs based on the evidence from that particular patient. Likewise, if a doctor said that a patient was likely experiencing two or more diseases, then I could change some of my link matrices to propagate the belief updates differently.
If you don't want to use something like Mongo for your system, but you are planning on having more than one consumer working on the knowledge base, you will need to adopt some sort of caching system to make sure that you are working on freshly-updated nodes at all times.
My work is open source, so you can follow along if you'd like. It's all Ruby, so it would be similar to your Python, but not necessarily a drop-in replacement. One thing that I like about my design is that all of the information needed for humans to interpret the results can be found in the nodes themselves, rather than in the code. This can be done in the qualitative descriptions, or in the structure of the network.
So, here are some important differences I have with your design:
- I don't compute the likelihood model inside the class, but rather between nodes, inside the link matrix. In this way, I don't have the problem of combining several likelihood functions inside the same class. I also don't have the problem of one model vs. another, I can just use two different contexts for the same knowledge base and compare results.
- I'm adding a lot of transparency by making the human decisions apparent. I.e., if I decide to use a default or-gate between two nodes, I know when I added that and that it was just a default decision. If I come back later and change the link matrix and re-calculate the knowledge base, I have a note about why I did that, rather than just an application that chose one method over another. You could have your consumers take notes about that kind of thing. However you solve that, it's probably a good idea to get the step-wise dialog from the analyst about why they are setting things up one way over another.
- I may be more explicit about prior odds and likelihoods. I don't know for sure on that, I just saw that you were using different models to change your likelihood numbers. Much of what I'm saying may be completely irrelevant if your model for computing posterior beliefs doesn't break down this way. I have the benefit of being able to make three asynchronous steps that can be called in any order: pass changed likelihoods up the network, pass changed prior odds down the network, and re-calculate the combined belief (posterior probability) of the node itself.
One big caveat: some of what I'm talking about hasn't been released yet. I worked on the stuff I am talking about until about 2:00 this morning, so it's definitely current and definitely getting regular attention from me, but isn't all available to the public just yet. Since this is a passion of mine, I'd be happy to answer any questions or work together on a project if you'd like.