Tesseract receipt scanning advice needed

I have struggled off and on again with Tesseract for various OCR projects and I found a use case today which I thought would be a slam dunk for it but after many hours I am still coming away unsatisfied. I wanted to pose the problem here and see if anyone else has advice on how to solve this task.
My wife came to me this morning and asked if there was anyway she could easily scan her receipts from Wal-Mart and over time build a history of prices spent in categories and for specific items so that we could do some trending and easily deep dive on where the spending is going. At first I felt like this was a very tall order, but after doing some digging I found a few things that make me feel this is within reach:
Wal-Mart receipts are in general, very well structured and easy to read. They even include the UPC for every item (potential for lookups against a UPC database?) and appear to classify food items with an F or I (not sure what the difference is) and have a tax code column as well that may prove useful should I learn the secrets of what the codes mean.
I further discovered that there is some kind of Wal-Mart item lookup API that I may be able to get access to which would prove useful in the UPC lookup.
They have an app for smart phones that lets you scan a QR code printed on every receipt. That app looks up a "TC" code off the receipt and pulls down the entire itemized receipt from their servers. It shows you an excellent graphical representation of the receipt including thumbnail pictures of all the items and the cost, etc. If this app would simply categorize and summarize the receipt, I would be done! But alas, that's not the purpose of the app ....
The final piece of the puzzle is that you can export a computer generated PNG image of the receipt in case you want to save it and throw away the paper version. This to me is the money shot, as these PNGs are computer created and therefore not subject to the issues surrounding taking a picture or scanning a paper receipt
An example of one of these (slightly edited to white out some areas but otherwise exactly as obtained from the app) is here:
https://postimg.cc/image/s56o0wbzf/
You can see that the important part of the text is perfectly aligned in 5 columns and that is ultimately what this question is about. How to get Tesseract to accurately OCR this into text. I have lots of ideas where to take it from here, but it all starts with the OCR!
The closest I have come myself is this example here:
I used psm6 and a character limiting set to force it to do uppercase + numbers + a few symbols only:
tessedit_char_whitelist 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ#()/*@%-.
At first glance, the OCR seems to almost match. But as you dig deeper you will see that it fails pretty horribly overall. 3s and 8s are almost always wrong. Same with 6s and 5s. Then there are times it just completely skips over characters or just starts to fall apart (like line 31+ in the example). It starts seeing 2s as 1s, or even just missing characters. The SO PIZZA on line 33 should be "2.82" but comes out as "32".
I have tried doing some pre-processing on the image to thicken up the characters and make sure it's pure black and white but none of my efforts got any closer than the raw image from Wal-Mart + the above commands.
Ideally since this is such a well structured PNG which is presumably always the same width I would love if I could define the columns by pixel widths so that Tesseract would treat each column independently. I tried to research this but the UZN files I've seen mentioned don't translate to me as far as pixel widths and they seem like height is a factor which wouldn't work on these since the height is always going to be variable.
In addition, I need to figure out how to train Tesseract to recognize the numbers 100% accurately (the letters aren't really important). I started researching how to train the program but to be honest it got over my head pretty quickly as the scope of training in the documentation is more for having it recognize entire languages not just 10 digits.
The ultimate end game solution would be a pipeline chain of commands that took the original PNG from the app and gave me back a CSV with the 5 columns of data from the important part of the receipt. I don't expect that out of this question, but any assistance guiding me towards it would be greatly appreciated! At this point I just don't feel like being whipped by Tesseract once again and so I am determined to find a way to master her!
Answer
I ended up fully flushing this out and am pretty happy with the results so I thought I would post it in case anyone else ever finds it useful.
I did not have to do any image splitting and instead used a regex since the Wal-mart receipts are so predictable.
I am on Windows so I created a powershell script to run the conversion commands and regex find & replace:
# -----------------------------------------------------------------
# Script: ParseReceipt.ps1
# Author: Jim Sanders
# Date: 7/27/2015
# Keywords: tesseract OCR ImageMagick CSV
# Comments:
# Used to convert a Wal-mart receipt image to a CSV file
# -----------------------------------------------------------------
param(
[Parameter(Mandatory=$true)] [string]$image
) # end param
# create output and temporary files based on input name
$base = (Get-ChildItem -Filter $image -File).BaseName
$csvOutfile = $base + ".txt"
$upscaleImage = $base + "_150.png"
$ocrFile = $base + "_ocr"
# upscale by 150% to ensure OCR works consistently
convert $image -resize 150% $upscaleImage
# perform the OCR to a temporary file
tesseract $upscaleImage -psm 6 $ocrFile
# column headers for the CSV
$newline = "Description,UPC,Type,Cost,TaxType`n"
$newline | Out-File $csvOutfile
# read in the OCR file and write back out the CSV (Tesseract automatically adds .txt to the file name)
$lines = Get-Content "$ocrFile.txt"
Foreach ($line in $lines) {
# This wraps the 12 digit UPC code and the price with commas, giving us our 5 columns for CSV
$newline = $line -replace '\s\d{12}\s',',$&,' -replace '.\d+\.\d{2}.',',$&,' -replace ',\s',',' -replace '\s,',','
$newline | Out-File -Append $csvOutfile
}
# clean up temporary files
del $upscaleImage
del "$ocrFile.txt"
The resulting file needs to be opened in Excel and then have the text to columns feature run so that it won't ruin the UPC codes by auto converting them to numbers. This is a well known problem I won't dive into, but there are a multitude of ways to handle and I settled on this slightly more manual way.
I would have been happiest to end up with a simple .csv I could double click but I couldn't find a great way to do that without mangling the UPC codes even more like by wrapping them in this format:
"=""12345"""
That does work but I wanted the UPC code to be just the digits alone as text in Excel in case I am able to later do a lookup against the Wal-mart API.
Anyway, here is how they look after importing and some quick formating:
https://s3.postimg.cc/b6cjsb4bn/Receipt_Excel.png
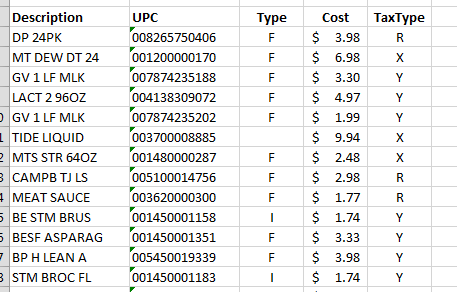{kind=link}
I still need to do some garbage cleaning on the rows that aren't line items but that all only takes a few seconds so doesn't bother me too much.
Thanks for the nudge in the right direction @RevJohn, I would not have thought to try simply scaling the image but that made all the difference in the world with Tesseract!